One weird trick to speed up feature teams!
Staff engineers hate this!

Table of Contents
When designing a new system or feature, it’s easy to get bogged down on schema design. In this article I will share a neat trick that has paid dividends over my career.
Try the simplest possible data persistence when designing a new system or feature.
All too often, I see teams reach for SQL or MongoDB as their only choice for data storage. Sure, no one’s getting fired for choosing SQL. But what if I told you there’s a simpler, faster, and cheaper way to start?
A KV or Key-value store might be all you need. Something like Redis or S3.
It’s not always the right choice, but perhaps more often than you realize.
A simple storage layer can moderately speed up early development by reusing data-layer code and avoiding costs related to churn in schema design and migrations. Churn will happen anyway; let the code deal with it as long as possible. Better to avoid dealing with changes in two places.
Performance gains are likely since key lookups are highly optimized, and writes can benefit from batched updates.
Thinking in Keys
It can feel strange to design with a Key-Value pattern first, especially if you’re used to designing systems with object hierarchies or Entity Relationship Diagrams and directly implementing them in SQL.
You’ve probably used key-value patterns before! They are everywhere, from configs and URLs to S3-style Object Storage! Every time you deal with data via a unique ID value, guess what? Another Key-value pattern! (Though not necessarily a KV Store.)
Designing with Keys
Virtually all data can be represented using KV patterns. (In fact, many higher-order DBs build on lower-level KV patterns.) Let’s look at some examples:
user/123 {id: 123, ...}user/123/block ['user/456', 'user/789']user/123/groups ['admin', 'staff']user/420/friends ['user/456', 'user/789']
group/admin {user: '*:rw'}group/default {user: '*:r'}
product/42/discount/<UUID> {percentOff: '10%'}product/42/discount/<UUID> {percentOff: '20%', minTotal: 100.0}You may have noticed, but the ID is often a key in itself! This is a common pattern in KV stores. The key is often a composite of the entity type and the unique identifier. (e.g user/123, user:456)
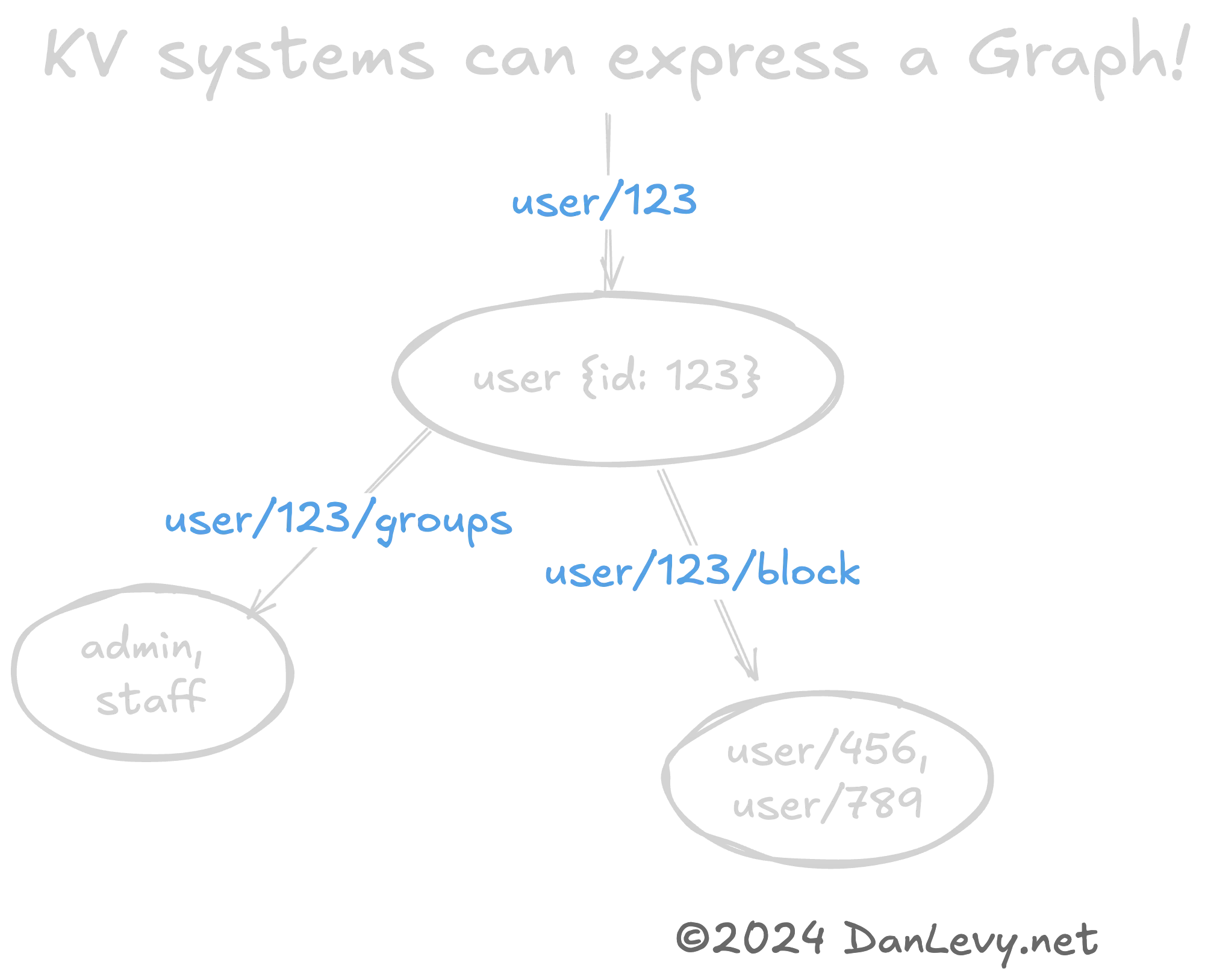
KVs as Graphs & Trees?
It can be helpful to represent complex data structures like Graphs or Trees using KV patterns. (Again, REST URLs are a great example of this.)
The key hierarchy (user/420 -> user/420/friends) naturally encodes a graph relationship between the user and their friends.
This is a quick & cheap way to serialize graph data structures. Especially if you don’t need the complexity of a graph database (like Neo4j).
When to Use KV Patterns
- When you need massive scale. (Billions or even trillions of KV pairs.)
- When you primarily access data via a unique key.
- When you need simple data structures.
- When you have data with a hierarchy, graph, or tree structure.
When to Avoid KV Patterns
Don’t store things like blog comments in a single KV pair. For example, post/666 -> {comments: [...too many...]}. Instead you might use post/666/comments/1, or post/666/comments/<UUID>, etc. Or go for a SQL table.
- When you need to search by properties (not Key or ID) in your dataset.
- When you need to JOIN data across multiple entities.
- When you need to enforce complex constraints or relationships.
When you need more than KV
As project requirements naturally evolve, you may need to do more than your KV store supports. At this point you’ll need to look at migrating to a more complex data store.
The good news is that migrating a single KV store to SQL is relatively easier than migrating a complex SQL schema into a KV store. (With multiple tables, indexes, constraints, etc.) I’ve done this many times with a 50-line script.
Anecdotally, I’ve found the quality of SQL designs is higher if you start with a KV pattern first. It forces you to really think about the data in a different way, and better understand exactly what you really need from SQL.
Next Steps
The best way to learn is to try it out! If you’re interested in exploring this pattern further, I recommend building things with Redis, DynamoDB or S3. All are excellent KV stores with different trade-offs.
Fact Service - Reference Project
Check out my Open Source “Fact Service,” a reference project on GitHub.
It’s a stand-alone RESTful API that implements a KV data service.
It features many data adapters. Including for Postgres, Redis, DynamoDB, Firestore, and Cassandra! (Complete with Docker commands to get started quickly.)
Fact Service is meant to be a starter & learning project, fork it and build your own KV data service!
Conclusion
I hope you found this article helpful! If you have any questions or feedback, please feel free to comment or @ me on Twitter.



