¡Un truco infalible para acelerar los equipos de desarrollo!
¡Los ingenieros senior lo odian!

Photo by Danny Howe on Unsplash
Tabla de Contenidos
Al diseñar un nuevo sistema o funcionalidad, es fácil perderse en el diseño del esquema de datos. En este artículo compartiré un truco sencillo que ha dado frutos a lo largo de mi carrera.
Prueba la forma más simple posible de persistencia de datos al diseñar un nuevo sistema o funcionalidad.
Con demasiada frecuencia, veo equipos recurrir a SQL o MongoDB como su única opción para almacenamiento de datos. Claro, nadie pierde el empleo por elegir SQL. Pero ¿y si te dijera que existe una forma más simple, rápida y económica de empezar?
Un almacén Clave-Valor (KV) podría ser todo lo que necesitas. Algo como Redis o S3.
No siempre es la opción correcta, pero quizá más a menudo de lo que crees.
Un almacenamiento simple puede acelerar moderadamente el desarrollo temprano al reutilizar código de la capa de datos y evitar costes relacionados con la iteración en el diseño de esquemas y migraciones. La iteración ocurrirá de todos modos; deja que el código la gestione el mayor tiempo posible. Mejor evitar lidiar con cambios en dos lugares.
Las ganancias de rendimiento son notables ya que las búsquedas por clave están altamente optimizadas, y las escrituras se benefician de actualizaciones por lotes.
Pensar en Claves
Puede resultar extraño diseñar primero con un patrón Clave-Valor, especialmente si estás acostumbrado a diseñar sistemas con jerarquías de objetos o diagramas entidad-relación e implementarlos directamente en SQL.
¡Probablemente ya has usado patrones Clave-Valor antes! Están por todas partes, desde configuraciones y URLs hasta el almacenamiento de objetos tipo S3. Cada vez que trabajas con datos mediante un valor ID único, ¿adivina qué? ¡Otro patrón Clave-Valor! (Aunque no necesariamente un almacén KV.)
Diseñar con Claves
Virtualmente todos los datos pueden representarse usando patrones Clave-Valor. (De hecho, muchas bases de datos de orden superior se construyen sobre patrones KV de nivel inferior.) Veamos algunos ejemplos:
user/123 {id: 123, ...}user/123/block ['user/456', 'user/789']user/123/groups ['admin', 'staff']user/420/friends ['user/456', 'user/789']
group/admin {user: '*:rw'}group/default {user: '*:r'}
product/42/discount/<UUID> {percentOff: '10%'}product/42/discount/<UUID> {percentOff: '20%', minTotal: 100.0}Quizá lo hayas notado, pero el ID suele ser una clave en sí mismo. Este es un patrón común en almacenes KV. La clave suele ser una composición del tipo de entidad y el identificador único (por ejemplo, user/123, user:456).
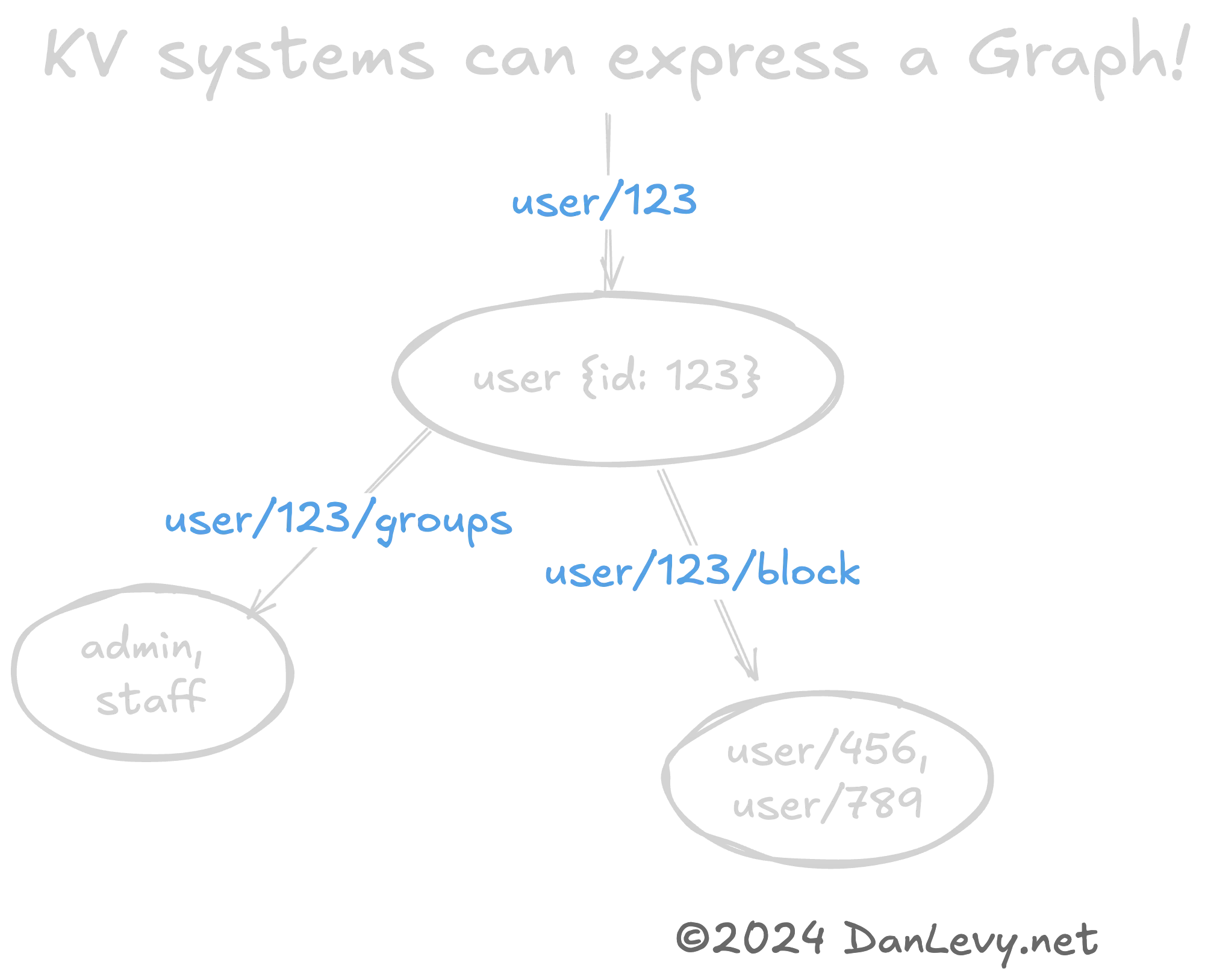
¿Clave-Valor como Grafos y Árboles?
Puede ser útil representar estructuras de datos complejas como grafos o árboles usando patrones Clave-Valor. (De nuevo, las URLs REST son un gran ejemplo de esto.)
La jerarquía de claves (user/420 -> user/420/friends) codifica naturalmente una relación de grafo entre el user y sus friends.
Esta es una forma rápida y económica de serializar estructuras de datos en grafo. Especialmente si no necesitas la complejidad de una base de datos de grafos (como Neo4j).
Cuándo Usar Patrones Clave-Valor
- Cuando necesitas escala masiva. (Miles de millones o incluso billones de pares Clave-Valor.)
- Cuando accedes principalmente a los datos mediante una clave única.
- Cuando necesitas estructuras de datos simples.
- Cuando tienes datos con una estructura de jerarquía, grafo o árbol.
Cuándo Evitar Patrones Clave-Valor
No almacenes cosas como comentarios de blog en un único par Clave-Valor. Por ejemplo, post/666 -> {comments: [...demasiados...]}. En su lugar, podrías usar post/666/comments/1, o post/666/comments/<UUID>, etc. O directamente una tabla SQL.
- Cuando necesitas buscar por propiedades (no por Clave o ID) en tu conjunto de datos.
- Cuando necesitas hacer JOINs de datos entre múltiples entidades.
- Cuando necesitas aplicar restricciones o relaciones complejas.
Cuando Necesitas Más que Clave-Valor
A medida que los requisitos del proyecto evolucionan naturalmente, puede que necesites hacer más de lo que tu almacén KV soporta. En ese punto, tendrás que considerar migrar a un almacén de datos más complejo.
La buena noticia es que migrar un único almacén KV a SQL es relativamente más fácil que migrar un esquema SQL complejo a un almacén KV. (Con múltiples tablas, índices, restricciones, etc.) He hecho esto muchas veces con un script de 50 líneas.
De forma anecdótica, he descubierto que la calidad de los diseños SQL es mayor si empiezas con un patrón Clave-Valor primero. Te obliga a pensar realmente en los datos de una forma diferente y a entender mejor exactamente qué necesitas de SQL.
Próximos Pasos
¡La mejor forma de aprender es probarlo! Si te interesa explorar este patrón más a fondo, te recomiendo construir cosas con Redis, DynamoDB o S3. Todos son excelentes almacenes Clave-Valor con diferentes compromisos.
Fact Service - Proyecto de Referencia
Echa un vistazo a mi proyecto Open Source “Fact Service”, una referencia en GitHub.
Es una API RESTful independiente que implementa un servicio de datos Clave-Valor.
Cuenta con numerosos adaptadores de datos. Incluye adaptadores para Postgres, Redis, DynamoDB, Firestore y Cassandra. (¡Con comandos de Docker para empezar rápidamente!)
Fact Service está pensado como un proyecto de inicio y aprendizaje. ¡Haz un fork y construye tu propio servicio de datos KV!
Conclusión
¡Espero que este artículo te haya resultado útil! Si tienes alguna pregunta o comentario, no dudes en escribir o mencionarme en Twitter.