Один странный способ ускорить команды разработки!
Старшие инженеры это ненавидят!

Photo by Danny Howe on Unsplash
Table of Contents
При проектировании новой системы или фичи легко увязнуть в проектировании схемы данных. В этой статье я поделюсь приёмом, который не раз окупал себя за мою карьеру.
Попробуйте наипростейшее возможное хранилище данных при проектировании новой системы или фичи.
Слишком часто команды тянутся к SQL или MongoDB как к единственному варианту хранения данных. Конечно, никто не будет рисковать, выбирая SQL. Но что, если я скажу, что есть более простой, быстрый и дешёвый способ начать?
Хранилище ключ-значение (KV) может быть всем, что вам нужно. Что-то вроде Redis или S3.
Это не всегда правильный выбор, но, возможно, чаще, чем вы думаете.
Простое хранилище данных может умеренно ускорить раннюю разработку за счёт переиспользования кода слоя данных и снижения затрат, связанных с изменениями в схеме и миграциями. Изменения всё равно будут происходить; пусть код разбирается с ними как можно дольше. Лучше избегать изменений в двух местах одновременно.
Производительность также вырастет, поскольку поиск по ключу сильно оптимизирован, а записи могут выигрывать от пакетных обновлений.
Thinking in Keys
Может показаться странным сначала проектировать с паттерном ключ-значение, особенно если вы привыкли проектировать системы с иерархиями объектов или диаграммами связей сущностей и напрямую реализовывать их в SQL.
Вы наверняка использовали паттерны ключ-значение раньше! Они повсюду: от конфигов и URL до S3-подобных объектных хранилищ! Каждый раз, когда вы работаете с данными через уникальный ID — угадайте что? Ещё один паттерн ключ-значение! (Хотя и не обязательно KV-хранилище.)
Designing with Keys
Практически все данные можно представить с помощью паттернов KV. (На самом деле, многие высокоуровневые базы данных строятся на низкоуровневых паттернах KV.) Давайте посмотрим на примеры:
user/123 {id: 123, ...}user/123/block ['user/456', 'user/789']user/123/groups ['admin', 'staff']user/420/friends ['user/456', 'user/789']
group/admin {user: '*:rw'}group/default {user: '*:r'}
product/42/discount/<UUID> {percentOff: '10%'}product/42/discount/<UUID> {percentOff: '20%', minTotal: 100.0}Вы могли заметить, но ID часто является частью ключа! Это распространённый паттерн в KV-хранилищах. Ключ часто составной: тип сущности и уникальный идентификатор (например, user/123, user:456).
KVs as Graphs & Trees?
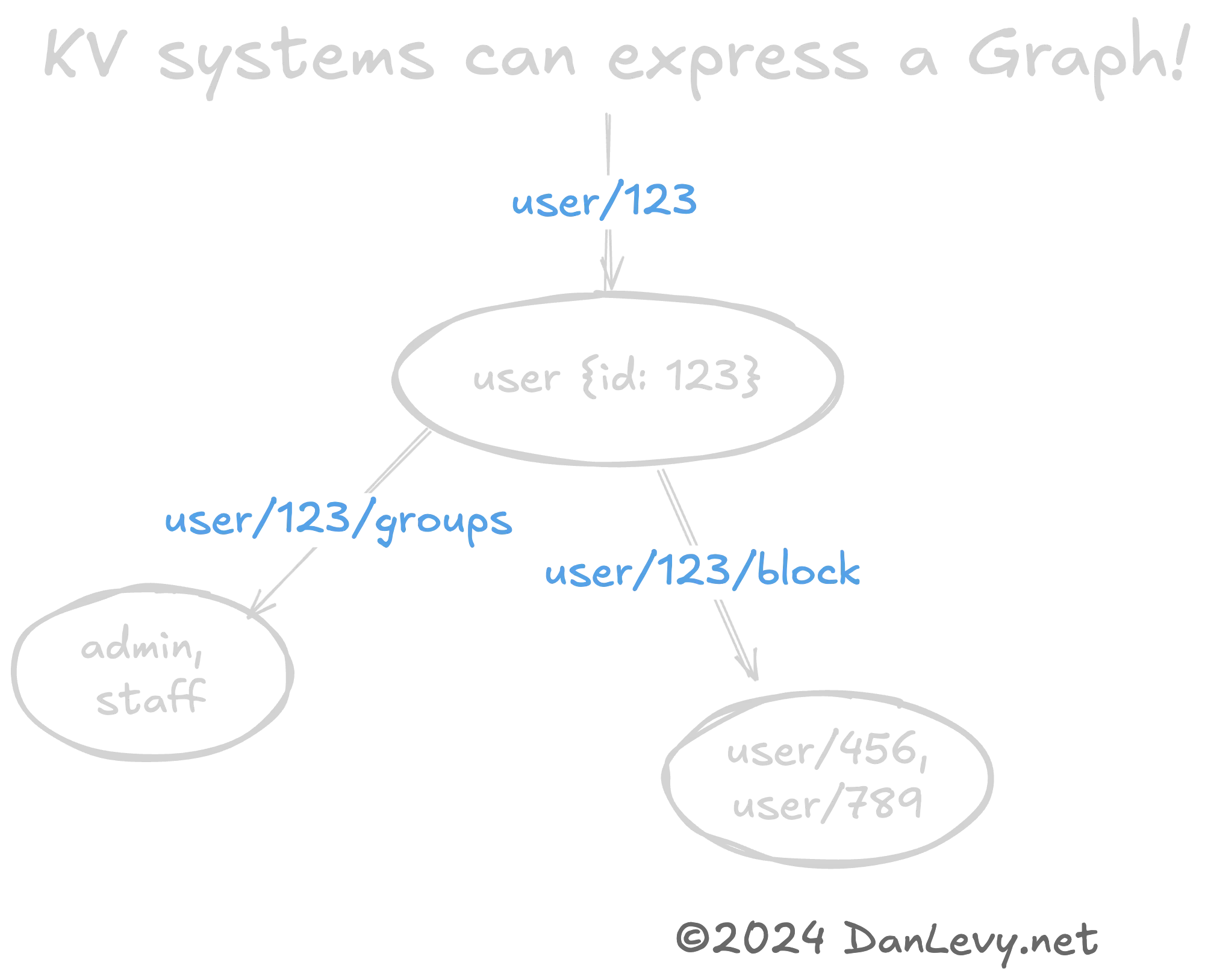
Можно полезно представлять сложные структуры данных, такие как графы или деревья, с помощью паттернов KV. (Опять же, URL-адреса REST — отличный пример этого.)
Иерархия ключей (user/420 → user/420/friends) естественным образом кодирует отношения графа между user и его friends.
Это быстрый и дешёвый способ сериализации графовых структур данных. Особенно если вам не нужна сложность графовой базы данных (вроде Neo4j).
When to Use KV Patterns
- Когда вам нужен масштаб. (Миллиарды или даже триллионы пар ключ-значение.)
- Когда вы в основном обращаетесь к данным через уникальный ключ.
- Когда вам нужны простые структуры данных.
- Когда у вас есть данные с иерархией, графовой или древовидной структурой.
When to Avoid KV Patterns
Не храните, например, комментарии к блогам в одной паре KV. Например, post/666 -> {comments: [...слишком много...]}. Вместо этого можно использовать post/666/comments/1 или post/666/comments/<UUID> и т. д. Или перейти к SQL-таблице.
- Когда нужно искать по свойствам (не по ключу или ID) в наборе данных.
- Когда нужно выполнять JOIN данных между несколькими сущностями.
- Когда нужно обеспечивать сложные ограничения или отношения.
When you need more than KV
По мере изменения требований проекта вам может понадобиться больше, чем поддерживает ваше KV-хранилище. В этот момент нужно рассмотреть миграцию на более сложное хранилище данных.
Хорошая новость: мигрировать одно KV-хранилище в SQL относительно проще, чем переносить сложную SQL-схему в KV-хранилище. (С множеством таблиц, индексов, ограничений и т. д.) Я делал это множество раз с помощью скрипта в 50 строк.
По моим наблюдениям, качество SQL-проектирования выше, если начать с паттерна KV. Это заставляет по-настоящему подумать о данных по-другому и лучше понять, что именно вам нужно от SQL.
Next Steps
Лучший способ научиться — попробовать! Если вам интересно изучить этот паттерн глубже, рекомендую создать что-нибудь с Redis, DynamoDB или S3. Все они — отличные KV-хранилища с разными trade-off’ами.
Fact Service - Reference Project
Посмотрите мой Open Source проект “Fact Service” на GitHub.
Это самостоятельный RESTful API, реализующий KV-сервис данных.
Он включает множество адаптеров данных. В том числе для Postgres, Redis, DynamoDB, Firestore и Cassandra! (С готовыми Docker-командами для быстрого старта.)
Fact Service создан как стартовый проект и источник знаний — форкните его и создайте свой KV-сервис!
Conclusion
Надеюсь, эта статья была полезна! Если у вас есть вопросы или отзывы, не стесняйтесь комментировать или писать мне в Twitter.