加速功能团队的奇妙一招!
资深工程师讨厌这个!

Photo by Danny Howe on Unsplash
在设计新系统或功能时,人们很容易陷入模式设计的泥潭。在本文中,我将分享一个在我的职业生涯中带来显著收益的小技巧。
在设计新系统或功能时,_尝试_使用最简单的数据持久化方式。
我经常看到团队在数据存储时只选择SQL或MongoDB。当然,选择SQL不会有人因此被解雇。但如果我告诉你,存在一种更简单、更快、更便宜的启动方式呢?
键值(KV)存储可能就是你所需要的一切。比如Redis或S3。
这并非总是正确的选择,但可能比你想象的更频繁适用。
一个简单的存储层可以通过复用数据层代码并避免与模式设计和迁移相关的成本,适度加速早期开发。变更无论如何会发生;让代码尽可能长时间地处理它。最好避免在两个地方同时处理变更。
性能提升是可能的,因为key查找高度优化,写入可受益于批量更新。
以键为中心的思考
如果习惯于通过对象层次结构或实体关系图直接在SQL中实现系统设计,那么首先使用键值模式设计可能会感觉很陌生。
你可能已经使用过键值模式!它们无处不在,从配置、URL到S3风格的对象存储!每次通过唯一ID值处理数据时,猜猜看?另一个键值模式!(尽管不一定是KV存储。)
以键设计
几乎所有数据都可以用KV模式表示。(事实上,许多高级数据库构建在低级KV模式之上。)让我们看一些示例:
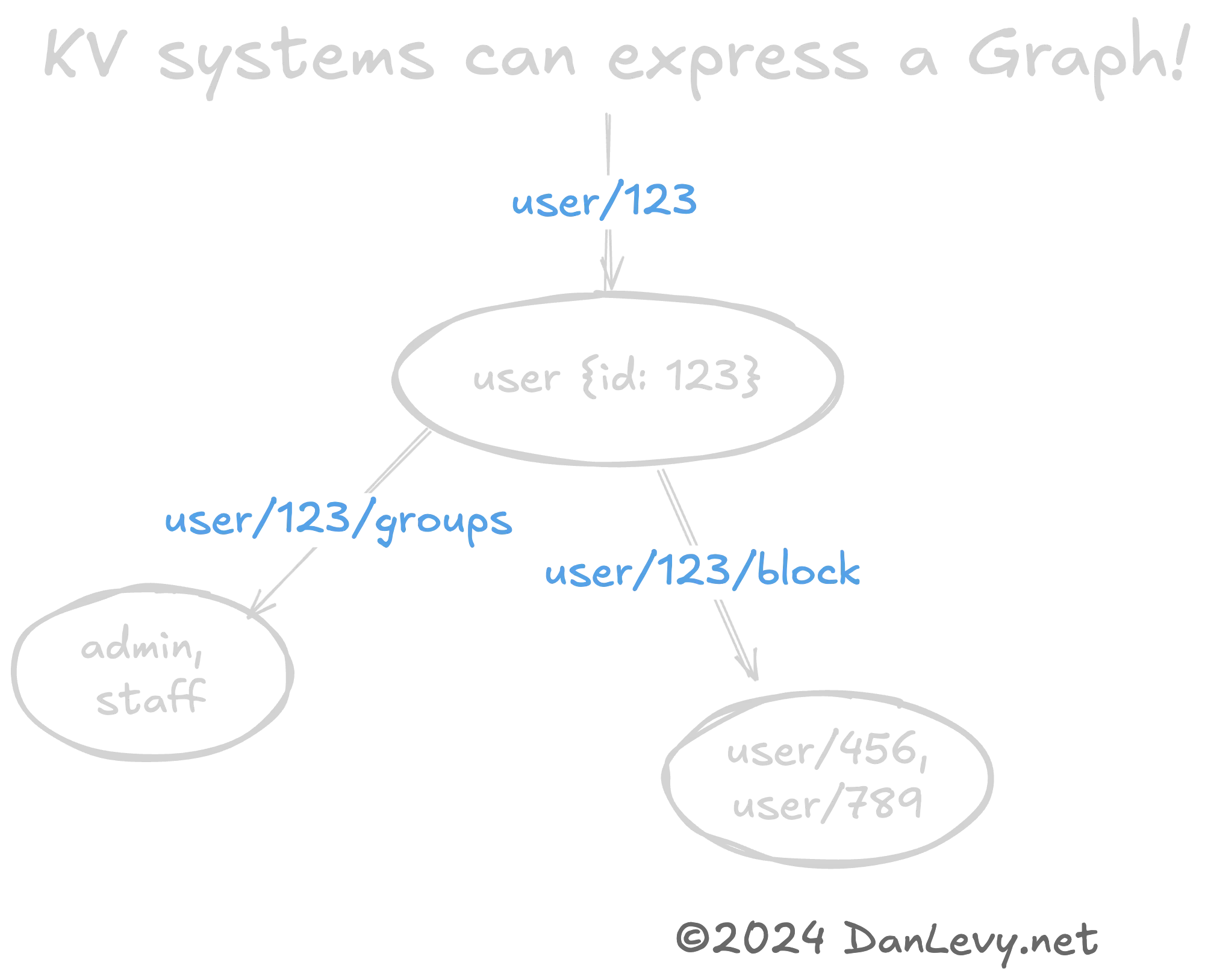
user/123 {id: 123, ...}user/123/block ['user/456', 'user/789']user/123/groups ['admin', 'staff']user/420/friends ['user/456', 'user/789']
group/admin {user: '*:rw'}group/default {user: '*:r'}
product/42/discount/<UUID> {percentOff: '10%'}product/42/discount/<UUID> {percentOff: '20%', minTotal: 100.0}你可能已经注意到,但ID本身通常就是键!这是KV存储中的常见模式。键通常是实体类型和唯一标识符的组合。(例如 user/123,user:456)
KV作为图和树?
使用KV模式表示图或树等复杂数据结构可能很有帮助。(再次强调,REST URL是这种模式的绝佳示例。)
键的层次结构(user/420 -> user/420/friends)自然地编码了user与其friends之间的图关系。
这是一种快速且低成本的图数据结构序列化方式。特别是当你不需要图数据库(如Neo4j)的复杂性时。
使用KV模式的场景
- 当你需要超大规模存储(数十亿甚至数万亿的KV对)时
- 当你主要通过唯一键访问数据时
- 当你需要简单数据结构时
- 当你的数据具有层次结构、图结构或树结构时
应避免使用KV模式的场景
不要将博客评论等数据存储在单个KV对中。例如post/666 -> {comments: [...too many...]}。更好的做法是使用post/666/comments/1或post/666/comments/<UUID>等结构,或者直接使用SQL表。
- 当你需要通过属性(而非键或ID)搜索数据时
- 当你需要跨多个实体进行JOIN操作时
- 当你需要强制执行复杂约束或关系时
当你需要KV之外的功能
随着项目需求的自然演进,你可能会发现KV存储的功能已无法满足需求。这时就需要考虑迁移到更复杂的数据存储系统。
好消息是,将单个KV存储迁移到SQL数据库通常比将复杂SQL模式迁移到KV存储要容易得多。(后者涉及多张表、索引、约束等)我曾多次通过50行脚本完成这种迁移。
从经验来看,如果先采用KV模式再设计SQL方案,最终的SQL设计质量往往更高。这种模式迫使你以不同的方式思考数据,并更清晰地理解自己真正需要的SQL功能。
下一步行动
最好的学习方式就是动手实践!如果你对这种模式感兴趣,我建议直接使用Redis、DynamoDB或S3构建实际项目。 它们都是优秀的KV存储系统,各有不同的权衡取舍。
Fact Service - 参考项目
查看我在GitHub上开源的”Fact Service”参考项目。
这是一个独立的RESTful API,实现了KV数据服务。
它包含许多data adapters。包括Postgres、Redis、DynamoDB、Firestore和Cassandra的适配器!(附带docker命令可快速启动。)
Fact Service旨在成为一个入门和学习项目,分叉它并构建自己的KV数据服务!
结论
希望本文对你有所帮助!如果有任何问题或反馈,请随时在Twitter上评论或@我。