फ़ीचर टीमों को तेज़ करने का एक अजीब ट्रिक!
वरिष्ठइंजीनियर इससे नफ़रत करते हैं!

Photo by Danny Howe on Unsplash
Table of Contents
जब आप कोई नया सिस्टम या फीचर डिजाइन कर रहे हों, तो स्कीमा डिज़ाइन में फँसना आसान है। इस लेख में मैं एक ऐसा ट्रिक साझा करूँगा जो मेरे करियर में लगातार लाभ देता आया है।
Try the simplest possible data persistence when designing a new system or feature.
बहुत बार मैं देखता हूँ कि टीमें डेटा स्टोरेज के लिए केवल SQL या MongoDB को ही चुनती हैं। हाँ, SQL चुनने से कोई नौकरी से नहीं निकाला जाएगा। लेकिन अगर मैं कहूँ कि शुरूआत करने का एक सरल, तेज़ और सस्ता तरीका है?
एक KV या Key‑value स्टोर शायद वही है जिसकी आपको ज़रूरत है। जैसे Redis या S3.
यह हमेशा सही विकल्प नहीं होता, लेकिन शायद आपके अनुमान से अधिक बार।
एक सरल स्टोरेज लेयर शुरुआती विकास को मध्यम गति से तेज़ कर सकती है, क्योंकि डेटा‑लेयर कोड को पुन: उपयोग किया जा सकता है और स्कीमा डिज़ाइन व माइग्रेशन से जुड़ी लागतों से बचा जा सकता है। स्कीमा में बदलाव तो होगा ही; कोड को जितना संभव हो उतना देर तक उन बदलावों को संभालने दें। दो जगहों पर बदलावों को संभालने से बचना बेहतर है।
प्रदर्शन में सुधार की संभावना रहती है क्योंकि key लुकअप अत्यधिक अनुकूलित होते हैं, और लिखने के कार्य बैच्ड अपडेट से लाभ उठा सकते हैं।
Keys के बारे में सोचना
पहले Key‑Value पैटर्न से डिज़ाइन करना अजीब लग सकता है, ख़ासकर जब आप ऑब्जेक्ट हायरार्की या एंटिटी रिलेशनशिप डायग्राम (ERD) से सिस्टम डिज़ाइन करने और उन्हें सीधे SQL में लागू करने के आदी हों।
आपनेशायद की‑वैल्यू पैटर्न पहले ही इस्तेमाल किए होंगे! वे हर जगह मिलते हैं, कॉन्फ़िग्स और URLs से लेकर S3‑स्टाइल ऑब्जेक्ट स्टोरेज तक! हर बार जब आप डेटा को एक अनूठे ID मान से एक्सेस करते हैं, तो क्या होता है? एक और की‑वैल्यू पैटर्न! (हालाँकि जरूरी नहीं कि वह KV स्टोर ही हो।)
Keys के साथ डिज़ाइन करना
व्यावहारिक रूप से सभी डेटा KV पैटर्न का उपयोग करके दर्शाया जा सकता है। (वास्तव में, कई हाई‑ऑर्डर डेटाबेस नीचे‑स्तर के KV पैटर्न पर निर्मित होते हैं.) चलिए कुछ उदाहरण देखते हैं:
user/123 {id: 123, ...}user/123/block ['user/456', 'user/789']user/123/groups ['admin', 'staff']user/420/friends ['user/456', 'user/789']
group/admin {user: '*:rw'}group/default {user: '*:r'}
product/42/discount/<UUID> {percentOff: '10%'}product/42/discount/<UUID> {percentOff: '20%', minTotal: 100.0}शायद आपने देखा होगा, ID अक्सर स्वयं में ही एक कुंजी होती है! यह KV स्टोर्स में एक सामान्य पैटर्न है. कुंजी अक्सर एंटिटी टाइप और अनूठे पहचानकर्ता का संयोजन होती है. (जैसे user/123, user:456)
KVs को ग्राफ़ या ट्री के रूप में?
जटिल डेटा संरचनाओं जैसे ग्राफ़ या ट्री को KV पैटर्न के माध्यम से दर्शाना उपयोगी हो सकता है. (फिर से, REST URLs इसका एक शानदार उदाहरण हैं.)
user/420 → user/420/friends की कुंजी पदानुक्रम स्वाभाविक रूप से user और उनके friends के बीच ग्राफ़ संबंध को एन्कोड करती है।
यह ग्राफ़ डेटा संरचनाओं को सीरियलाइज़ करने का तेज़ और सस्ता तरीका है। विशेष रूप से जब आपको ग्राफ़ डेटाबेस (जैसे Neo4j) की जटिलता की आवश्यकता नहीं होती।
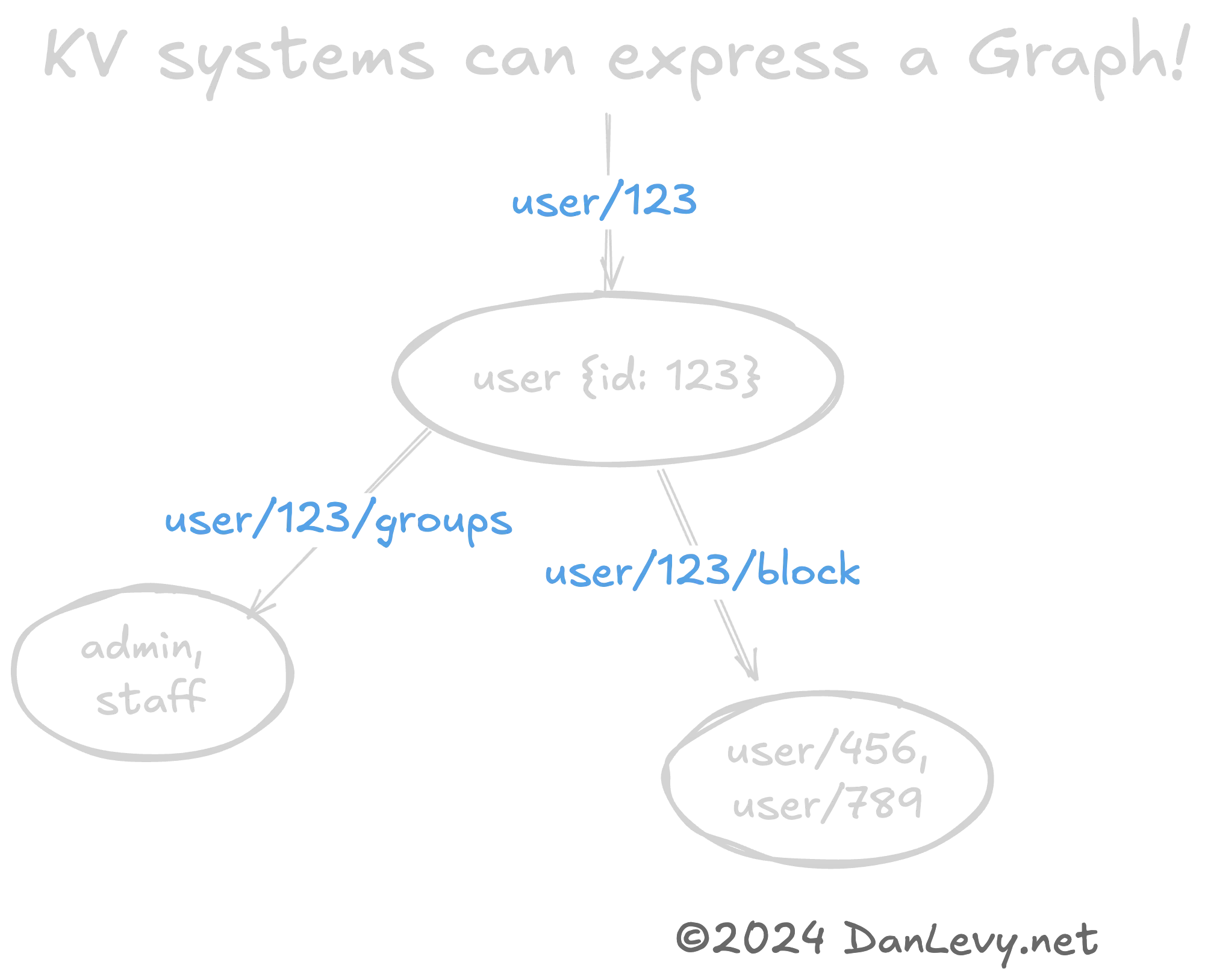
KV पैटर्न कब उपयोग करें
- जब आपको बहुत बड़े पैमाने की आवश्यकता हो। (अरबों या यहाँ तक कि खरबों KV जोड़े।)
- जब आप मुख्यतः डेटा को एक अद्वितीय कुंजी द्वारा एक्सेस करते हैं।
- जब आपको सरल डेटा संरचनाएँ चाहिए।
- जब आपके डेटा में पदानुक्रम, ग्राफ़ या ट्री संरचना हो।
KV पैटर्न से बचने के मामले
एकल KV जोड़ी में ब्लॉग टिप्पणियों जैसी चीज़ें न रखें। उदाहरण के लिए, post/666 -> {comments: [...too many...]}. इसके बजाय आप post/666/comments/1 या post/666/comments/<UUID> आदि का उपयोग कर सकते हैं, या फिर एक SQL तालिका बना सकते हैं।
- जब आपको अपने डेटा सेट में गुणों (Key या ID नहीं) के आधार पर खोज करनी हो।
- जब आपको कई इकाइयों के बीच डेटा को JOIN करना हो।
- जब आपको जटिल प्रतिबंधों या संबंधों को लागू करना हो।
जब आपको KV से अधिक चाहिए
जैसे-जैसे प्रोजेक्ट की आवश्यकताएँ विकसित होती हैं, आपको KV स्टोर की क्षमताओं से अधिक करने की ज़रूरत पड़ सकती है। इस चरण पर आपको अधिक जटिल डेटा स्टोर की ओर माइग्रेट करने पर विचार करना होगा।
अच्छी बात यह है कि एकल KV स्टोर को SQL में माइग्रेट करना, जटिल SQL स्कीमा को KV स्टोर में माइग्रेट करने की तुलना में अपेक्षाकृत आसान है। (कई तालिकाएँ, इंडेक्स, प्रतिबंध आदि के साथ)। मैंने इसे कई बार 50‑लाइन स्क्रिप्ट से किया है।
अनुभवजन्य रूप से, मैंने देखा है कि यदि आप पहले KV पैटर्न से शुरू करते हैं तो SQL डिज़ाइनों की गुणवत्ता अधिक होती है। यह आपको डेटा को अलग तरीके से सोचने के लिए मजबूर करता है, और ठीक‑ठीक समझाता है कि आपको SQL से वास्तव में क्या चाहिए।
अगले कदम
सबसे अच्छा तरीका सीखने का है कि खुद आज़माएँ! यदि आप इस पैटर्न को आगे खोजने में रुचि रखते हैं, तो मैं बनाते हुए Redis, DynamoDB या S3 के साथ काम करने की सलाह देता हूँ। ये सभी अलग‑अलग ट्रेड‑ऑफ़ के साथ उत्कृष्ट KV स्टोर हैं।
Fact Service - रेफ़रेंस प्रोजेक्ट
मेरे ओपन सोर्स “Fact Service,” एक रेफ़रेंस प्रोजेक्ट GitHub पर को देखें।
यह एक स्टैंड‑अलोन RESTful API है जो KV डेटा सेवा को लागू करता है।
यह कई डेटा एडेप्टर प्रदान करता है।
Postgres, Redis, DynamoDB, Firestore, और Cassandra के लिए भी शामिल हैं! (तेज़ शुरुआत के लिए Docker कमांड्स के साथ पूरा किया गया है।)
Fact Service को एक शुरुआती और सीखने‑परियोजना के रूप में बनाया गया है; इसे फ़ोर्क करके अपना स्वयं का KV डेटा सर्विस बनाइए!
निष्कर्ष
आशा है कि यह लेख आपके काम आया होगा! यदि आपके कोई प्रश्न या प्रतिक्रिया हों, तो कृपया टिप्पणी करें या Twitter पर @ करके संपर्क करें।
श्रेय
- PostgreSQL में पदानुक्रमित ट्री डेटा मॉडलिंग
- PostgreSQL में बड़े ट्रीज़ को स्टोर करने के Do’s और Don’ts