Une astuce peu conventionnelle pour accélérer les équipes fonctionnelles !
Les staff engineers détestent ça!

Photo by Danny Howe on Unsplash
Table of Contents
Lors de la conception d’un nouveau système ou d’une nouvelle fonctionnalité, il est facile de se bloquer sur la conception de schémas. Dans cet article, je partage un truc utile qui m’a apporté des bénéfices tout au long de ma carrière.
Essayez la persistance de données la plus simple possible lors de la conception d’un nouveau système ou d’une nouvelle fonctionnalité.
Trop souvent, je vois des équipes opter pour SQL ou MongoDB comme seule option de stockage de données. Certes, personne n’est licencié pour avoir choisi SQL. Mais que diriez-vous s’il existait une approche plus simple, plus rapide et moins coûteuse pour commencer ?
Un magasin de paires clé-valeur (KV) pourrait être tout ce dont vous avez besoin. Quelque chose comme Redis ou S3.
Ce n’est pas toujours le bon choix, mais peut-être plus souvent que vous ne le réalisez.
Une couche de stockage simple peut accélérer modérément le développement précoce en réutilisant le code de la couche de données et en évitant les coûts liés aux changements dans la conception des schémas et les migrations. Les changements surviendront de toute façon ; laissez le code s’en charger aussi longtemps que possible. Mieux vaut éviter de gérer les changements dans deux endroits.
Les gains de performance sont probables puisque les recherches par key sont hautement optimisées, et les écritures peuvent bénéficier des mises à jour par lots.
Penser en Clés
Il peut sembler étrange de concevoir d’abord avec un modèle clé-valeur, surtout si vous êtes habitué à concevoir des systèmes avec des hiérarchies d’objets ou des Diagrammes Entité-Relation et à les implémenter directement en SQL.
Vous avez probablement utilisé des modèles clé-valeur avant ! Ils sont partout, des configurations et des URLs jusqu’au stockage d’objets de type S3 ! Chaque fois que vous manipulez des données via une valeur ID unique, devinez quoi ? Un autre modèle clé-valeur ! (Bien que ce ne soit pas nécessairement un magasin clé-valeur.)
Conception avec des clés
Presque toutes les données peuvent être représentées à l’aide de modèles clé-valeur. (En fait, de nombreuses bases de données de haut niveau s’appuient sur des modèles clé-valeur de bas niveau.) Examinons quelques exemples :
user/123 {id: 123, ...}user/123/block ['user/456', 'user/789']user/123/groups ['admin', 'staff']user/420/friends ['user/456', 'user/789']
group/admin {user: '*:rw'}group/default {user: '*:r'}
product/42/discount/<UUID> {percentOff: '10%'}product/42/discount/<UUID> {percentOff: '20%', minTotal: 100.0}Vous avez peut-être remarqué, mais l’ID est souvent une clé en soi ! C’est un modèle courant dans les magasins clé-valeur. La clé est souvent une combinaison du type d’entité et de l’identifiant unique. (Par exemple user/123, user:456)
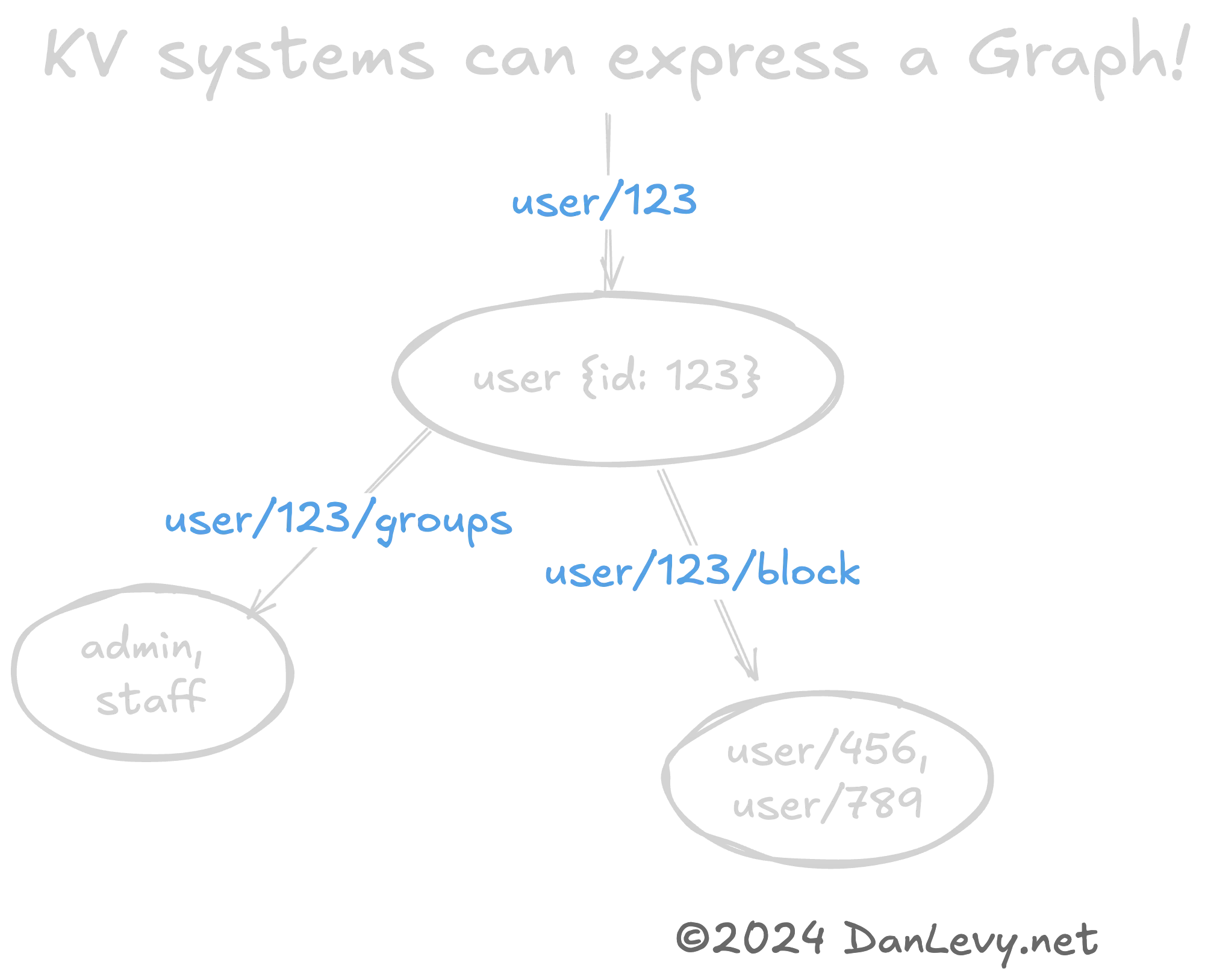
Les KVs comme Graphes & Arbres ?
Il peut être utile de représenter des structures de données complexes comme des Graphes ou des Arbres en utilisant des modèles clé-valeur. (Encore une fois, les URLs REST sont un excellent exemple de cela.)
La hiérarchie des clés (user/420 -> user/420/friends) encodage naturel d’une relation graphique entre l’user et ses friends.
C’est une méthode rapide et peu coûteuse pour sérialiser des structures de données graphiques. Surtout si vous n’avez pas besoin de la complexité d’une base de données graphique (comme Neo4j).
Quand utiliser les modèles KV
- Quand vous avez besoin d’une échelle massive. (Des milliards, voire des trillions de paires clé-valeur.)
- Quand vous accédez principalement aux données via une clé unique.
- Quand vous avez besoin de structures de données simples.
- Quand vos données ont une structure hiérarchique, graphique ou arborescente.
Quand éviter les modèles KV
Ne stockez pas des éléments comme les commentaires de blog dans une paire clé-valeur unique. Par exemple, post/666 -> {comments: [...too many...]}. Utilisez plutôt post/666/comments/1, ou post/666/comments/<UUID>, etc. Ou encore, optez pour une table SQL.
- Quand vous devez rechercher par des propriétés (et non par clé ou ID) dans votre ensemble de données.
- Quand vous devez effectuer des JOIN entre plusieurs entités.
- Quand vous devez imposer des contraintes ou des relations complexes.
Quand vous avez besoin de plus que KV
À mesure que les exigences de votre projet évoluent naturellement, vous pourriez avoir besoin de faire plus que ce que votre magasin KV ne peut supporter. À ce stade, vous devrez envisager de migrer vers un système de stockage plus complexe.
La bonne nouvelle est que la migration d’un seul magasin KV vers SQL est relativement plus facile que la migration d’un schéma SQL complexe vers un magasin KV. (Avec plusieurs tables, index, contraintes, etc.) J’ai réalisé cela de nombreuses fois avec un script de 50 lignes.
D’après mon expérience, la qualité des conceptions SQL est meilleure si vous commencez par un modèle KV. Cela vous pousse à vraiment penser aux données d’une manière différente et à mieux comprendre exactement ce dont vous avez vraiment besoin en SQL.
Étapes suivantes
Le meilleur moyen d’apprendre est de l’essayer ! Si vous êtes intéressé par l’exploration de ce modèle, je vous recommande de construire des choses avec Redis, DynamoDB ou S3. Tous sont d’excellents magasins KV avec des compromis différents.
Fact Service - Projet de référence
Découvrez mon open source “Fact Service”, un projet de référence sur GitHub.
C’est une API REST autonome qui implémente un service de données KV.
Il comporte de nombreux adaptateurs de données. Y compris pour Postgres, Redis, DynamoDB, Firestore et Cassandra ! (Avec des commandes Docker pour commencer rapidement.)
Le Fact Service est conçu pour être un projet de départ et d’apprentissage, fork-le et construis ton propre service de données KV !
Conclusion
J’espère que cet article vous a été utile ! Si vous avez des questions ou des retours, n’hésitez pas à commenter ou à me @ sur Twitter.
Crédits
- Modélisation des données hiérarchiques en arbre dans PostgreSQL
- Bonnes et mauvaises pratiques pour stocker de grands arbres en PostgreSQL