Ein einfacher Trick, um Feature-Teams zu beschleunigen!
Staff Engineers hassen das!

Foto von Danny Howe auf Unsplash
Inhaltsverzeichnis
Beim Entwurf eines neuen Systems oder Features fällt es leicht, sich im Schema-Design zu verlieren. In diesem Artikel teile ich einen einfachen Trick, der sich im Laufe meiner Karriere ausgezahlt hat.
Versuche die einfachstmögliche Datenpersistenz beim Entwurf eines neuen Systems oder Features.
Viel zu oft sehe ich Teams, die zu SQL oder MongoDB als einziger Wahl für die Datenspeicherung greifen. Klar, niemand wird gefeuert, weil er SQL wählt. Aber was, wenn es einen einfacheren, schnelleren und günstigeren Weg gibt, um anzufangen?
Ein KV- oder Key-Value-Speicher könnte alles sein, was du brauchst. Etwas wie Redis oder S3.
Es ist nicht immer die richtige Wahl, aber vielleicht häufiger, als du denkst.
Eine einfache Speicherschicht kann die frühe Entwicklung moderat beschleunigen, indem Data-Layer-Code wiederverwendet und Kosten durch ständige Änderungen am Schema-Design und Migrationen vermieden werden. Änderungen werden sowieso kommen; lass den Code so lange wie möglich damit umgehen. Besser, als Änderungen an zwei Stellen zu pflegen.
Leistungssteigerungen sind wahrscheinlich, da key-Lookups hochoptimiert sind und Writes von Batch-Updates profitieren können.
In Keys denken
Es kann sich seltsam anfühlen, zuerst mit einem Key-Value-Pattern zu designen, besonders wenn du es gewohnt bist, Systeme mit Objekthierarchien oder Entity-Relationship-Diagrammen zu entwerfen und sie direkt in SQL zu implementieren.
Du hast Key-Value-Patterns wahrscheinlich schon verwendet! Sie sind überall – von Configs und URLs bis hin zu S3-Object-Storage! Jedes Mal, wenn du mit Daten über einen eindeutigen ID-Wert arbeitest, was dann? Ein weiteres Key-Value-Pattern! (Aber nicht unbedingt ein KV-Speicher.)
Mit Keys designen
Nahezu alle Daten können mit KV-Patterns dargestellt werden. (Tatsächlich bauen viele höherwertige DBs auf niedrigeren KV-Patterns auf.) Schauen wir uns einige Beispiele an:
user/123 {id: 123, ...}user/123/block ['user/456', 'user/789']user/123/groups ['admin', 'staff']user/420/friends ['user/456', 'user/789']
group/admin {user: '*:rw'}group/default {user: '*:r'}
product/42/discount/<UUID> {percentOff: '10%'}product/42/discount/<UUID> {percentOff: '20%', minTotal: 100.0}Vielleicht hast du es bemerkt, aber die ID ist oft selbst ein Key! Das ist ein häufiges Pattern in KV-Speichern. Der Key ist oft eine Kombination aus Entitätstyp und eindeutigem Bezeichner. (z. B. user/123, user:456)
KVs als Graphen & Bäume?
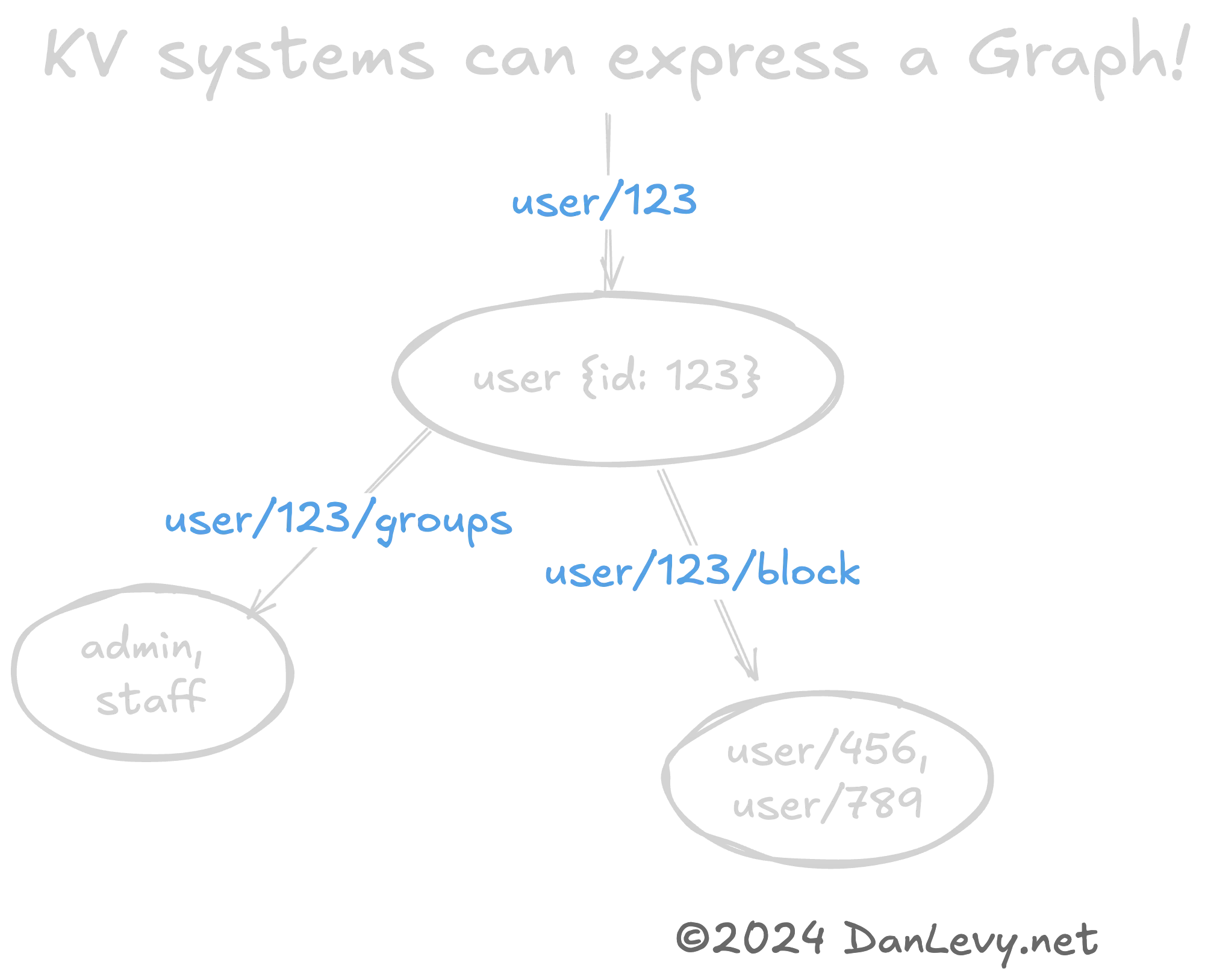
Es kann hilfreich sein, komplexe Datenstrukturen wie Graphen oder Bäume mit KV-Patterns darzustellen. (Auch hier sind REST-URLs ein großartiges Beispiel dafür.)
Die Key-Hierarchie (user/420 -> user/420/friends) kodiert auf natürliche Weise eine Graph-Beziehung zwischen dem user und seinen friends.
Das ist eine schnelle und günstige Möglichkeit, Graph-Datenstrukturen zu serialisieren. Besonders wenn du nicht die Komplexität einer Graph-Datenbank (wie Neo4j) brauchst.
Wann KV-Patterns einsetzen
- Wenn du massive Skalierung brauchst. (Milliarden oder sogar Billionen von KV-Paaren.)
- Wenn du hauptsächlich über einen eindeutigen Key auf Daten zugreifst.
- Wenn du einfache Datenstrukturen brauchst.
- Wenn du Daten mit einer Hierarchie-, Graph- oder Baumstruktur hast.
Wann KV-Patterns vermeiden
Speichere Dinge wie Blog-Kommentare nicht in einem einzelnen KV-Paar. Zum Beispiel post/666 -> {comments: [...zu viele...]}. Stattdessen könntest du post/666/comments/1 oder post/666/comments/<UUID> usw. verwenden. Oder greife zu einer SQL-Tabelle.
- Wenn du nach Eigenschaften (nicht Key oder ID) in deinem Datensatz suchen musst.
- Wenn du Daten über mehrere Entitäten hinweg JOINen musst.
- Wenn du komplexe Constraints oder Beziehungen durchsetzen musst.
Wenn du mehr als KV brauchst
Wenn sich die Projektanforderungen auf natürliche Weise weiterentwickeln, brauchst du vielleicht mehr, als dein KV-Speicher unterstützt. An diesem Punkt musst du die Migration zu einem komplexeren Datenspeicher in Betracht ziehen.
Die gute Nachricht ist, dass die Migration eines einzelnen KV-Speichers zu SQL relativ einfacher ist, als ein komplexes SQL-Schema in einen KV-Speicher zu migrieren. (Mit mehreren Tabellen, Indizes, Constraints usw.) Ich habe das viele Male mit einem 50-Zeilen-Skript gemacht.
Aus Erfahrung habe ich festgestellt, dass die Qualität von SQL-Designs höher ist, wenn du zuerst mit einem KV-Pattern beginnst. Es zwingt dich, die Daten wirklich auf eine andere Art zu betrachten und besser zu verstehen, genau was du von SQL wirklich brauchst.
Nächste Schritte
Der beste Weg zu lernen ist, es auszuprobieren! Wenn du daran interessiert bist, dieses Pattern weiter zu erkunden, empfehle ich, Dinge zu bauen mit Redis, DynamoDB oder S3. Alle sind ausgezeichnete KV-Speicher mit unterschiedlichen Trade-offs.
Fact Service – Referenzprojekt
Schau dir mein Open-Source-”Fact Service,” ein Referenzprojekt auf GitHub an.
Es ist eine eigenständige RESTful API, die einen KV-Datenservice implementiert.
Es enthält viele Data-Adapter. Unter anderem für Postgres, Redis, DynamoDB, Firestore und Cassandra! (Komplett mit Docker-Befehlen für einen schnellen Einstieg.)
Fact Service ist als Starter- und Lernprojekt gedacht, forke es und baue deinen eigenen KV-Datenservice!
Fazit
Ich hoffe, dieser Artikel war hilfreich! Wenn du Fragen oder Feedback hast, kommentiere gerne oder schreib mir auf Twitter.