Independent senior consulting
Your AI app works great.
Mostly.
I help teams go from "it works in the demo" to "it works in production" — with agentic coding, eval-driven development, and architecture that holds up when real users show up.
- Agentic delivery with evals — not just vibes and hope
- Parallel agent exploration instead of one slow serial plan
- Production AI design grounded in actual failure cases

How it started "GPT-3.5 sure can generate code!"
How it's going Our swarm of Agents completed & tested 183 tickets before lunch. Six regressions were caught and fixed.
How I work
No surprises. Just results.
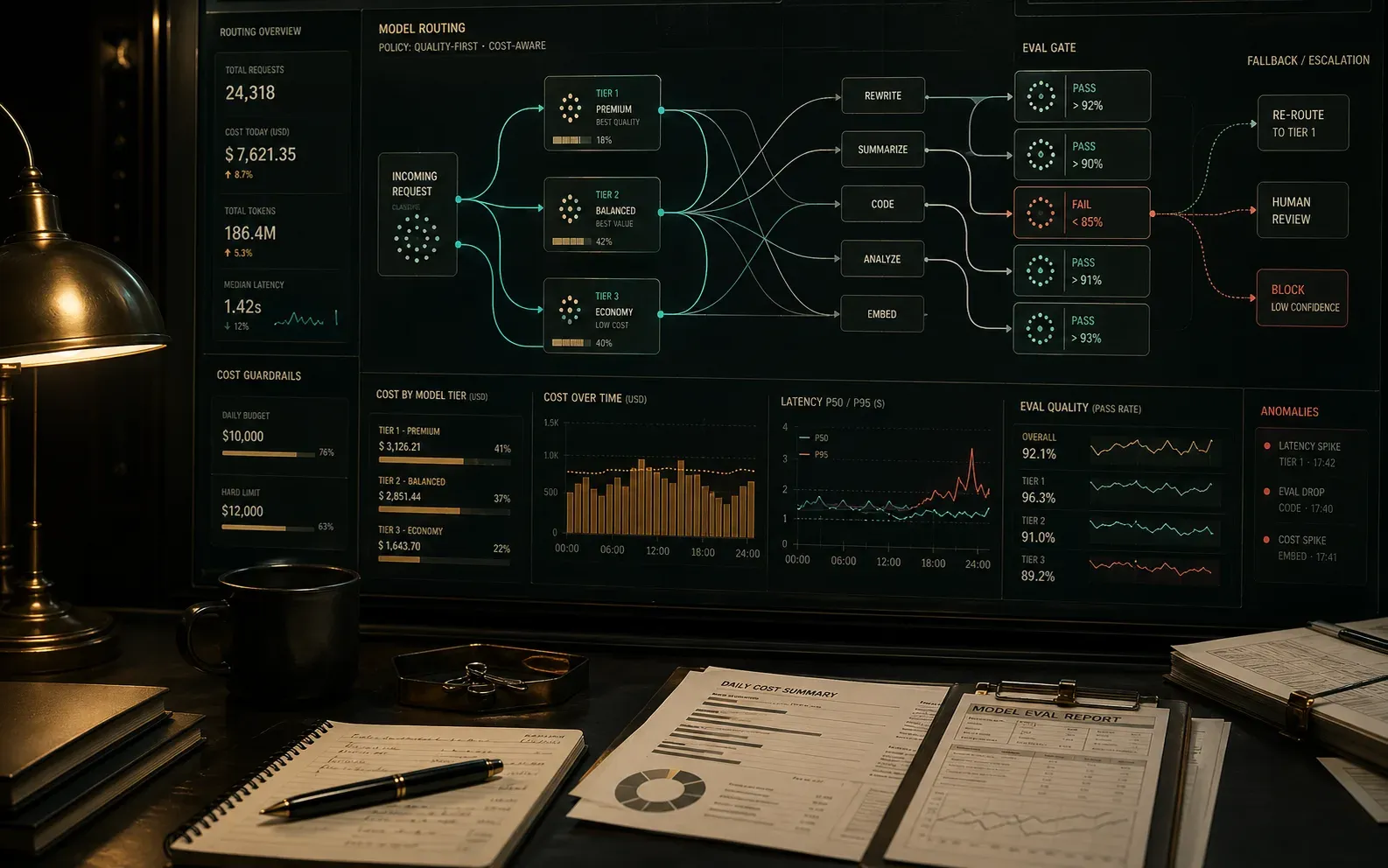
Every engagement starts with a diagnostic — your logs, costs, incidents, and failure cases — so we both know exactly what we're fixing before any work begins. Deliverables are defined up front. You'll know what done looks like.
Services
Pick your flavor of "we need help."
Whether your AI app is too expensive, too unpredictable, or just too scary to touch — there's a service for that.
AI
AI Consulting
AI Consulting
Your AI costs are climbing and the answers are inconsistent. Build the routing, evals, and observability that fix both.
Explore service
GR
AI Guardrails
AI Guardrails
Your users are creative. Add policy controls, review paths, and eval gates before they find the fun edge cases.
Explore service
SB
Supabase Scaling & Migration
Supabase Scaling
Your auth bill is bigger than your office rent. Let's fix that — with agents exploring the migration in parallel.
Explore service
RG
RAG Rescue
RAG Rescue
RAG worked great at 500 docs. At 50,000 it's hallucinating confidently. Time to rebuild retrieval properly.
Explore service
CS
Developer AI Coding Security
AI Coding Security
AI coding tools are fast. That's the problem. Add sandboxes, access controls, and CI gates before they are.
Explore service
ES
Whole Enterprise Security Assessment
Enterprise Security
Security debt accumulates quietly until it doesn't. Find the compound risks before they find you.
Explore serviceEvidence
Results, not slides.
Migrations that used to take quarters. Auth bills that were eating the runway. RAG systems that worked great until they didn't. Real problems, fixed.
Case Study · Supabase Scaling
A company was spending $22,500 every month just to authenticate users.
Before a major ad campaign, I helped them migrate off that setup to better-auth in under one month. The campaign landed, their user base grew 14x, and the new architecture held when adoption climbed.
Today, the same class of work can be accelerated further by letting agents explore migration paths in parallel while tests decide what is safe to keep.Case Study · RAG Rescue
A company’s knowledgebase integration was wildly successful until it fell over.
At roughly 25,000 to 50,000 indexed documents, they started seeing context collapse, semantic confusion, and degraded answer quality. I rebuilt retrieval around a highly optimized three-layer hybrid search design, with graphRAG only kicking in when the query context justified the extra depth.
The fix was not one more prompt tweak. It was retrieval architecture.How I work
Not "throw agents at it."
Define what done looks like. Let agents explore in parallel. Use evals and senior judgment to pick the parts that actually work. Ship the thing. Repeat.
Start diagnostic call
Define the target
Turn architecture goals, failure cases, and product expectations into tests and evals.
Fan out
Use agentic coding to explore multiple implementation paths in parallel instead of betting on one.
Converge
Compare the outputs, combine the strongest pieces, and discard approaches that fail the checks.
Ship with proof
Land the change with eval coverage, observability, and handoff notes your team can keep using.
DL
Dan Levy
Work directly with Dan Levy.
I work with a small number of companies each year. No account managers, no junior handoffs — just senior judgment near the implementation. Shaping agentic workflows, reviewing architecture, building evals, and helping ship changes your team can actually explain to each other.
AI systems Guardrails RAG Supabase Security
Good fit
Your AI app works great in the demo. In production it's... creative.
You've been "adding guardrails next sprint" for four sprints now
The migration estimate keeps growing and nobody wants to own it
Next step
Bring the thing your team keeps not finishing.
The migration everyone's afraid to start. The agentic app that only works in staging. The AI product that's expensive and nobody's sure why. Let's figure out what's actually wrong and fix it.